A Spry XML Data Set is a JavaScript object that you can use to display data from an XML data source file on a web page. You can then use this data to create master and detail regions on the page that update as site visitors make different selections. A version of this file is available on Adobe LiveDocs. Please check it for comments and updates.
A Spry data set is fundamentally a JavaScript object. With a few snippets of code in your web page, you can create this object and load data from an XML source into the object when the user opens the page in a browser. The data set results in a flattened array of XML data that can be represented as a standard table containing rows and columns.
For example, suppose you have an XML source file, cafetownsend.xml, that contains the following information:
<?xml version="1.0" encoding="UTF-8"?> <specials> <menu_item id="1"> <item>Summer Salad</item> <description>organic butter lettuce with apples, blood oranges, gorgonzola, and raspberry vinaigrette.</description> <price>7</price> </menu_item> <menu_item id="2"> <item>Thai Noodle Salad</item> <description>lightly sauteed in sesame oil with baby bok choi, portobello mushrooms, and scallions.</description> <price>8</price> </menu_item> <menu_item id="3"> <item>Grilled Pacific Salmon</item> <description>served with new potatoes, diced beets, Italian parlsey, and lemon zest.</description> <price>16</price> </menu_item> </specials>
Using XPath in your web page to indicate the data you're interested in (in this example, the specials/menu_item node of the XML file), the data set flattens the XML data into an array of objects (rows) and properties (columns), represented by the following table.
| @id |
item |
description |
price |
|---|---|---|---|
1 |
Summer salad |
organic butter lettuce with apples, blood oranges, gorgonzola, and raspberry vinaigrette. |
7 |
2 |
Thai Noodle Salad |
lightly sauteed in sesame oil with baby bok choi, portobello mushrooms, and scallions. |
8 |
3 |
Grilled Pacific Salmon |
served with new potatoes, diced beets, Italian parlsey, and lemon zest. |
16 |
The data set contains a row for each menu item and the following columns: @id, item, description, and price. The columns represent the child nodes of the specials/menu_item node in the XML, plus any attributes contained in the menu_item tag, or in any of the child tags of the menu_item tag.
The data set also contains a built-in data reference called ds_RowID (not shown) that can be useful later when you display your data. Additionally the data set includes other built-in data references, for example, ds_RecordCount, ds_CurrentRow, and others that you can use to manipulate the data display.
You create a Spry data set object by using XPath in the Spry.Data.XMLDataSet constructor. The XPath defines the default structure of the data set. For example, if you use XPath to select a repeating XML node that includes three child nodes, the data set will have a row for each repeating node, and a column for each of the three child nodes. (If any of the repeating nodes or child nodes contain attributes, the data set also creates a column for each attribute.)
If you do not specify an XPath, all of the data in the XML source will be included in the data set.
After the data set is created, the data set object lets you easily display and manage the data. For example, you can create a simple table that displays the XML data, and then use simple methods and properties to reload, sort and filter, or page through data.
The following example creates a Spry data set called dsSpecials, and loads data from an XML file called cafetownsend.xml:
<head>
<meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1" />
<title>Spry Example</title>
<!--Link the Spry libraries-->
<script type="text/javascript" src="includes/xpath.js"></script>
<script type="text/javascript" src="includes/SpryData.js"></script>
<!--Create a data set object-->
<script type="text/javascript">
var dsSpecials = new Spry.Data.XMLDataSet("data/cafetownsend.xml", "specials/menu_item");
</script>
</head>
. . .
<body>
</body>
Note: The examples in this document
are for reading purposes only and not intended for execution. For working
samples, see the demos folder in the Spry folder on Adobe Labs.
In the example, the first script tag links an open-source XPath library to the page where you'll eventually display XML data. The XPath library allows for the specification of a more complex XPath when you create a data set:
<script type="text/javascript" src="includes/xpath.js"></script>
The second script block links the SpryData.js Spry data library, which is stored in a folder called includes on the server:
<script type="text/javascript" src="includes/SpryData.js"></script>
The Spry data library depends on the XPath library, so it's important that you always link the XPath library first.
The third script block contains the statement that creates the dsSpecials data set. The cafetownsend.xml XML source file is stored in a folder called data on the server:
var dsSpecials = new Spry.Data.XMLDataSet("data/cafetownsend.xml", "specials/menu_item");
Note: Remember that JavaScript and
XML are case-sensitive languages, so it's important that you make sure that the
scripts and column names you specify are capitalized (or not capitalized)
appropriately.
In JavaScript the new operator is used to create objects. The Spry.Data.XMLDataSet method is a constructor in the Spry data library that creates new Spry data set objects. The constructor takes two parameters: the source of the data ("data/cafetownsend.xml", in this case, a relative URL) and an XPath expression that specifies the node or nodes in the XML to supply the data ("specials/menu_item").
You can also specify an absolute URL as the source of the XML data, as follows:
var dsSpecials = new Spry.Data.XMLDataSet("http://www.somesite.com/somefolder/cafetownsend.xml", "specials/menu_item");
Note: The URL you decide to use
(whether absolute or relative) is subject to the browser's security model, which
means that you can only load data from an XML source that is on the same server
domain as the HTML page you're linking from. You can avoid this limitation by
providing a cross-domain service script. For more information, consult your
server administrator.
In the preceding example, the constructor creates a new dsSpecials Spry data set object. The data set obtains data from the specials/menu_item node (specified by XPath) in the cafetownsend.xml XML file and converts the data to a flattened array of objects and properties, similar to the rows and columns of a table. (For an example of the table, see the beginning of this section.)
Each data set maintains the notion of a current row. By default, the current row is set to the first row in the data set. Later, you can change the current row programmatically by calling the setCurrentRow() method on the data set object.
Note: The data set contains no data after you've created it with the new JavaScript operator. To load data into the dataset, first call the data set's loadData() method, which executes a request to load the XML data. Spry regions and detail regions do this automatically for the data sets they depend on, but if you are not using one of these regions, call the loadData() method manually in your page code. This loading is asynchronous, so the data might still be unavailable if you try to access it immediately after calling loadData().Spry XML data sets use the XMLHTTPRequest object to asynchronously load the specified URL. When the XML data arrives, it is actually in two formats: a text format, and a document object model (DOM) tree format.
For example, say that you've specified “/photos.php?galleryid=2000" as your data source. (This is a path to a web service that retrieves XML data).
<script type="text/javascript">
var dsPhotos = new Spry.Data.XMLDataSet("/photos.php?galleryid=2000", "/gallery/photos/photo");
</script>
The following code represents the data as it arrives in text format:
<gallery id="12345"> <photographer id="4532">John Doe</photographer> <email>john@doe.com</email> <photos id="2000"> <photo path="sun.jpg" width="16" height="16" /> <photo path="tree.jpg" width="16" height="16" /> <photo path="surf.jpg" width="16" height="16" /> </photos> </gallery>
The following example represents the data as it arrives in DOM-tree format.
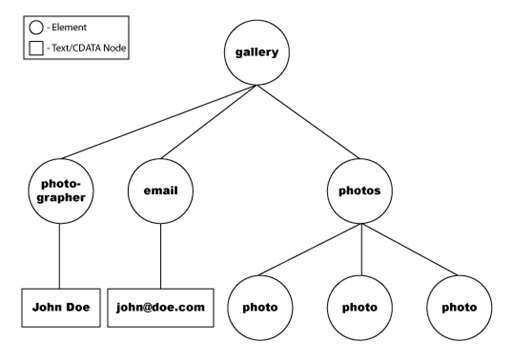
The data set then uses the XPath specified in the constructor to navigate the XML DOM tree to find the particular nodes that represent the data you are interested in.
The following code shows data selected with the /gallery/photos/photo XPath, in bold:
<gallery id="12345"> <photographer id="4532">John Doe</photographer> <email>john@doe.com</email> <photos id="2000"> <photo path="sun.jpg" width="16" height="16"/> <photo path="tree.jpg" width="16" height="16"/> <photo path="surf.jpg" width="16" height="16"/> </photos> </gallery>
The following example is the DOM-tree representation of the selected nodes.
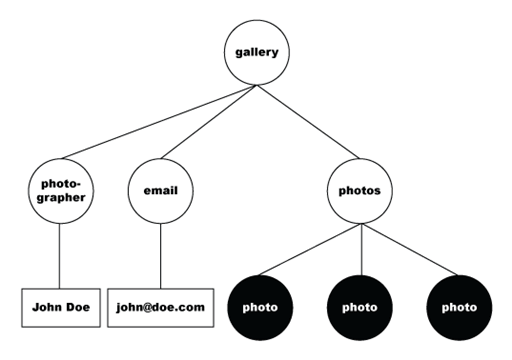
The data set then flattens the set of nodes into a tabular format, which the following table represents.
| @path |
@width |
@height |
|---|---|---|
sun.jpg |
16 |
16 |
tree.jpg |
16 |
16 |
surf.jpg |
16 |
16 |
In this instance, Spry derives the column names of the flattened table from the selected nodes and their attributes. The way Spry determines column names, however, can vary, depending on the XPath you specify.
Spry uses the following guidelines when flattening data and creating columns:
If the selected node has attributes, Spry creates a column for each attribute and places the value of the attribute in that column. The names for these columns are the names of the attributes preceded by an @ sign. For example, if a node has an id attribute, the column name is @id.
If the selected node has no element children, and has text or CDATA underneath it, then Spry creates a column and places that text or CDATA in that column. The name of this column is the tag name of the node for normal XML elements.
If the selected node has element children, Spry creates a column for the value of each element and its attributes, but only for each element child that has no element children of its own. The names of the columns are the tag names of the children elements, or in the case of an attribute on a child element, the format "childTagName/@attrName".
If the selected node is an attribute, Spry creates a column for the attribute, and the column name is the name of the attribute preceded by an @ sign.
Spry ignores element children that have their own element children.
The examples that follow provide more details on the flattening process and how Spry generates column names for data sets.
The following code shows data selected with the /gallery/photographer XPath, in bold:
<gallery id="12345"> <photographer id="4532">John Doe</photographer> <email>john@doe.com</email> <photos id="2000"> <photo path="sun.jpg" width="16" height="16" /> <photo path="tree.jpg" width="16" height="16" /> <photo path="surf.jpg" width="16" height="16" /> </photos> </gallery>
The following is the DOM-tree representation of the selected node.
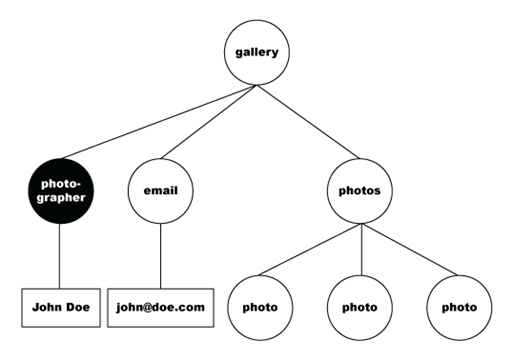
The data set then flattens the selected data into the following table.
| photographer |
@id |
|---|---|
John Doe |
16 |
In this particular case, only one node is selected, so we only get one row in our data set. The value of the photographer node is the text "John Doe", so a column named photographer is created to store that value. The id attribute is an attribute of the photographer node, so its value is placed in the @id column. All attribute names are preceded by an @ sign.
The following code shows data selected with the /gallery XPath:
<gallery id="12345"> <photographer id="4532">John Doe</photographer> <email>john@doe.com</email> <photos id="2000"> <photo path="sun.jpg" width="16" height="16" /> <photo path="tree.jpg" width="16" height="16" /> <photo path="surf.jpg" width="16" height="16" /> </photos> </gallery>
The following is the DOM-tree representation of the selected node:
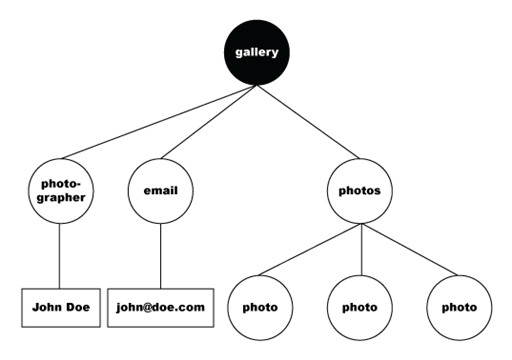
The data set then flattens the selected data into the following table.
| @id |
photographer |
photographer/@id |
|
|---|---|---|---|
12345 |
John Doe |
4532 |
john@doe.com |
Notice that the column names for attributes of children elements are prefixed with the tag name of the child element. In this particular case, photographer is a child element of the selected gallery node, so its id attribute is prefixed with photographer/@. Also notice that nothing was added to the table for the photos element, even though it is a child of the gallery node. That is because Spry does not flatten any child elements that contain other elements.
With XPath you can also select attributes of nodes. The following code shows data selected with the gallery/photos/photo/@path XPath, in bold:
<gallery id="12345"> <photographer id="4532">John Doe</photographer> <email>john@doe.com</email> <photos id="2000"> <photo path="sun.jpg" width="16" height="16" /> <photo path="tree.jpg" width="16" height="16" /> <photo path="surf.jpg" width="16" height="16" /> </photos> </gallery>
The following is the DOM-tree representation of the selected nodes.
The data set then flattens the selected data into the following table.
| @path |
|---|
sun.jpg |
tree.jpg |
surf.jpg |
After you've created a Spry data set, you can display the data in a Spry dynamic region. A Spry dynamic region is an area on a web page that's bound to a data set. The region displays the XML data from the data set and automatically updates the data display whenever the data set is modified.
Dynamic regions regenerate because they register themselves as observers or listeners of the data sets to which they are bound. Whenever data in any of these data sets is modified (loaded, updated, sorted, filtered, and so on), the data sets send notifications to all of their observers, triggering an automatic regeneration by the listening dynamic regions.
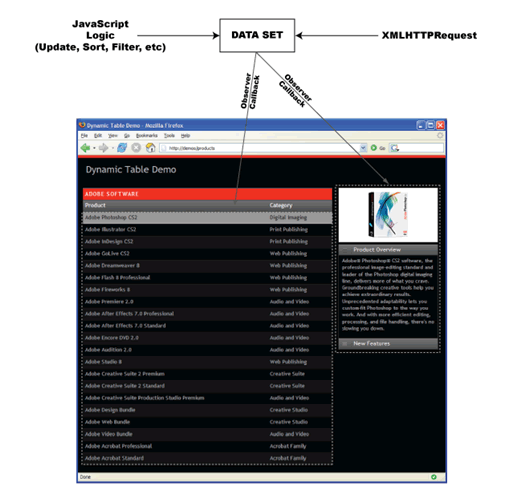
To declare a Spry dynamic region in a container tag, use the spry:region attribute. Most HTML elements can act as dynamic-region containers, however, the following tags cannot be used:
col
colgroup
frameset
html
iframe
select
style
table
tbody
tfoot
thead
title
tr
While you cannot use any of the preceding HTML elements as Spry dynamic region containers, you can use them inside Spry dynamic-region containers.
Note: Dynamic regions are limited to regions within the body tag. You can't add the spry:region attribute to any tag that is outside the body tag.In the following example, a container for a dynamic region called Specials_DIV is created using a div tag that includes a standard HTML table. Tables are typical HTML elements used for dynamic regions because the first row of the table can contain headings, and the second row can contain repeated XML data.
<!--Create the Spry dynamic region-->
<div id="Specials_DIV" spry:region="dsSpecials">
<!--Display the data in a table-->
<table id="Specials_Table">
<tr>
<th>Item</th>
<th>Description</th>
<th>Price</th>
</tr>
<tr spry:repeat="dsSpecials">
<td>{item}</td>
<td>{description}</td>
<td>{price}</td>
</tr>
</table>
</div>
In the example, the div tag that creates the container for the dynamic region needs only two attributes: a spry:region attribute that declares the dynamic region and specifies the data set to use in it, and an id attribute that names the region:
<div id="Specials_DIV" spry:region="dsSpecials">
The new region is an observer of the dsSpecials data set. Any time the dsSpecials data set changes, the new dynamic region regenerates itself with the updated data.
An HTML table displays the data:
<table id="Specials_Table">
<tr>
<th>Item</th>
<th>Description</th>
<th>Price</th>
</tr>
<tr spry:repeat="dsSpecials">
<td>{item}</td>
<td>{description}</td>
<td>{price}</td>
</tr>
</table>
The values in curly braces in the second row of the table—the data references—specify the columns in the data set. The data references bind the table cells to the data in specific columns of the data set. Because XML data often includes repeating nodes, the example also declares a spry:repeat attribute in the second table row tag. This causes all of the rows in the data set to appear when the user loads the page (instead of just the data set's current row).
When working with Spry data sets, you can create master and detail dynamic regions to display more detail about your data. One region on the page (the master), drives the display of the data in another region on the page (the detail).
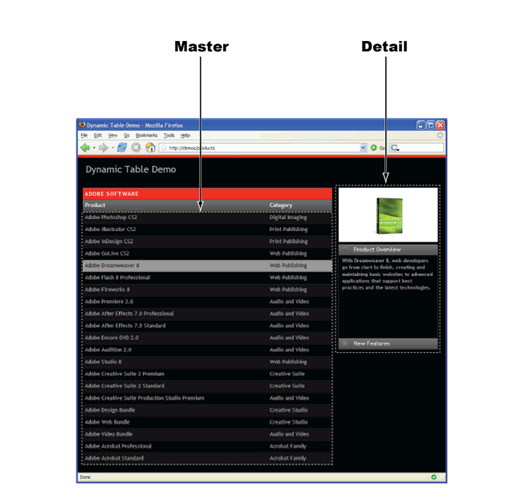
Typically, the master region displays an abbreviated form of a set of records from the data set, and the detail region displays more information about a selected record. Because the detail region depends on the master region, any time the data in the master region changes, the data in the detail region changes as well.
This section covers basic master and detail relationships where both regions are dependent on the same data set.
In the following example, a master dynamic region displays data from the dsSpecials data set, and a detail dynamic region displays more detail about the row of data that's been selected in the master region:
<head>
. . .
<script type="text/javascript" src="../includes/xpath.js"></script>
<script type="text/javascript" src="../includes/SpryData.js"></script>
<script type="text/javascript">
var dsSpecials = new Spry.Data.XMLDataSet("data/cafetownsend.xml", "specials/menu_item");
</script>
</head>
. . .
<body>
<!--Create a master dynamic region-->
<div id="Specials_DIV" spry:region="dsSpecials">
<table id="Specials_Table">
<tr>
<th>Item</th>
<th>Description</th>
<th>Price</th>
</tr>
<!--User clicks to reset the current row in the data set-->
<tr spry:repeat="dsSpecials" spry:setrow="dsSpecials">
<td>{item}</td>
<td>{description}</td>
<td>{price}</td>
</tr>
</table>
</div>
<!--Create the detail dynamic region-->
<div id="Specials_Detail_DIV" spry:detailregion="dsSpecials">
<table id="Specials_Detail_Table">
<tr>
<th>Ingredients</th>
<th>Calories</th>
</tr>
<tr>
<td>{ingredients}</td>
<td>{calories}</td>
</tr>
</table>
</div>
. . .
</body>
In the example, the first div tag contains the id and spry:region attributes that create a container for the master dynamic region:
<div id="Specials_DIV" spry:region="dsSpecials">
The first table-row tag of the master region contains a spry:setrow attribute that sets the value of the current row in the data set.
<tr spry:repeat="dsSpecials" spry:setrow="dsSpecials">
The second div tag contains the attributes that create a container for the detail dynamic region:
<div id="Specials_Detail_DIV" spry:detailregion="dsSpecials">
Every Spry data set maintains the notion of a current row. By default, the current row is set to the first row in the data set. A spry:detailregion works in exactly the same way as a spry:region except that when the data set's current row changes, the detail region updates automatically.
The binding expressions in the detail region ({ingredients} and {calories}) display data from the data set's current row when the page loads in a browser. When a user clicks a row in the master region table, however, the spry:setrow attribute changes the current row in the data set to the row the user selected.
The {ds_RowID} data reference is a built-in part of the Spry framework that points to an automatically generated unique ID for each row in the data set. When the user selects a row in the master region table, the spry:setrow attribute supplies the unique ID to the setCurrentRow method, which sets the current row in the data set.
Whenever the data set is modified, all dynamic regions bound to that data set regenerate themselves and display the updated data. Because the detail region, like the master region, is an observer of the dsSpecials data set, it also changes as a result of the modification, and displays data related to the row the user selected (the new current row).
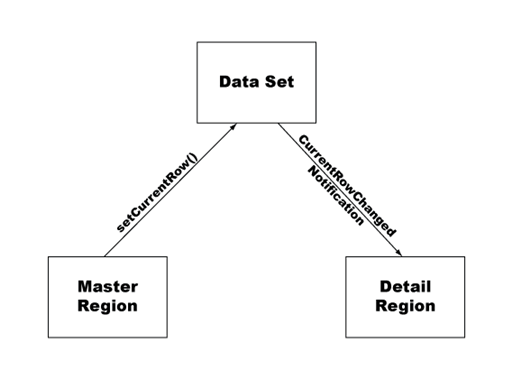
The difference between a spry:region and a spry:detailregion is that the spry:detailregion specifically listens for CurrentRowChange notifications (in addition to DataChanged notifications) from the data set, and updates itself when it receives one. Normal spry:regions, on the other hand, ignore the CurrentRowChange notification, and only update when they receive a DataChanged notification from the data set.
In some cases, you might want to create master and detail relationships that involve more than one data set. For example, you might have a list of menu items that has a great deal of detail information associated with it. (This section uses a list of ingredients to illustrate the point.) Fetching all of the information associated with every menu item in a single query might be an inefficient use of bandwidth not to mention unnecessary, given that many users might not even be interested in the details of everything on the menu. Instead, it is more efficient to download only the detail data that the user is interested in when the user requests it, thus improving performance and reducing bandwidth. Limiting the amount of data exchange in this way is a common technique used to improve performance in AJAX applications.
Following is the XML source code for a sample file called cafetownsend.xml:
<?xml version="1.0" encoding="UTF-8"?> <specials> <menu_item id="1"> <item>Summer Salad</item> <description>organic butter lettuce with apples, blood oranges, gorgonzola, and raspberry vinaigrette.</description> <price>7</price> <url>summersalad.xml</url> </menu_item> <menu_item id="2"> <item>Thai Noodle Salad</item> <description>lightly sauteed in sesame oil with baby bok choi, portobello mushrooms, and scallions.</description> <price>8</price> <url>thainoodles.xml</url> </menu_item> <menu_item id="3"> <item>Grilled Pacific Salmon</item> <description>served with new potatoes, diced beets, Italian parlsey, and lemon zest.</description> <price>16</price> <url>salmon.xml</url> </menu_item> </specials>
The cafetownsend.xml file supplies the data for the master data set. The url node of the cafetownsend.xml file points to a unique XML file (or URL) for each menu item. These unique XML files contain a list of ingredients for the corresponding menu items. The summersalad.xml file, for example, might look as follows:
<?xml version="1.0" encoding="UTF-8" ?> <item> <item_name>Summer salad</item_name> <ingredients> <ingredient> <name>butter lettuce</name> </ingredient> <ingredient> <name>Macintosh apples</name> </ingredient> <ingredient> <name>Blood oranges</name> </ingredient> <ingredient> <name>Gorgonzola cheese</name> </ingredient> <ingredient> <name>raspberries</name> </ingredient> <ingredient> <name>Extra virgin olive oil</name> </ingredient> <ingredient> <name>balsamic vinegar</name> </ingredient> <ingredient> <name>sugar</name> </ingredient> <ingredient> <name>salt</name> </ingredient> <ingredient> <name>pepper</name> </ingredient> <ingredient> <name>parsley</name> </ingredient> <ingredient> <name>basil</name> </ingredient> </ingredients> </item>
When you are familiar with the structure of your XML code, you can create two data sets to use to display data in master and detail dynamic regions. In the following example, a master dynamic region displays data from the dsSpecials data set, and a detail dynamic region displays data from the dsIngredients data set:
<head>
. . .
<script type="text/javascript" src="../includes/xpath.js"></script>
<script type="text/javascript" src="../includes/SpryData.js"></script>
<script type="text/javascript">
<!--Create two separate data sets-->
var dsSpecials = new Spry.Data.XMLDataSet("data/cafetownsend.xml", "specials/menu_item");
var dsIngredients = new Spry.Data.XMLDataSet("data/{dsSpecials::url}", "item/ingredients/ingredient");
</script>
</head>
. . .
<body>
<!--Create a master dynamic region-->
<div id="Specials_DIV" spry:region="dsSpecials">
<table id="Specials_Table">
<tr>
<th>Item</th>
<th>Description</th>
<th>Price</th>
</tr>
<!--User clicks to reset the current row in the data set-->
<tr spry:repeat="dsSpecials" spry:setrow="dsSpecials">
<td>{item}</td>
<td>{description}</td>
<td>{price}</td>
</tr>
</table>
</div>
<!--Create the detail dynamic region-->
<div id="Specials_Detail_DIV" spry:region="dsIngredients">
<table id="Specials_Detail_Table">
<tr>
<th>Ingredients</th>
</tr>
<tr spry:repeat="dsIngredients">
<td>{name}</td>
</tr>
</table>
</div>
. . .
</body>
In the example, the third script block contains the statement that creates two data sets, one called dsSpecials and one called dsIngredients:
var dsSpecials = new Spry.Data.XMLDataSet("data/cafetownsend.xml", "specials/menu_item");
var dsIngredients = new Spry.Data.XMLDataSet("data/{dsSpecials::url}", "item/ingredients/ingredient");
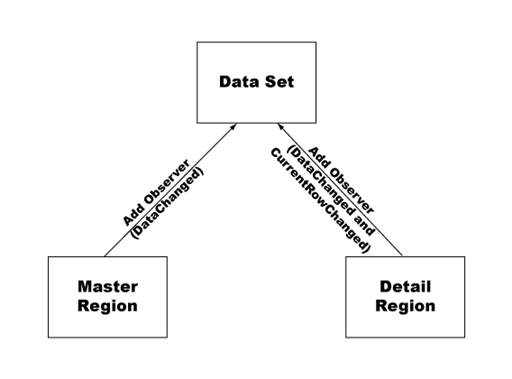
The URL for the second data set, dsIngredients, contains a data reference ({dsSpecials::url}) to the first data set, dsSpecials. More specifically, it contains a data reference to the url column in the dsSpecials data set. When the URL or XPath argument in the constructor that creates a data set contains a reference to another data set, the data set being created automatically becomes an observer of the data set it's referencing. The new data set depends on the original data set, and reloads its data or reapplies its XPath whenever the data or current row changes in the original data set.
The following example shows the observer relationships established between data sets and master and detail dynamic regions. In the preceding example, the dsIngredients data set (data set B) is an observer of the dsSpecials data set (data set A).
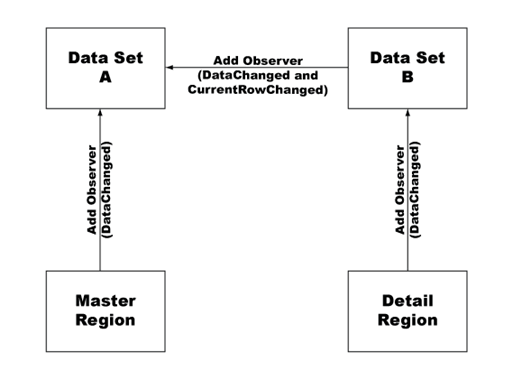
In the example, changing the current row in the dsSpecials data set sends a notification to the dsIngredients data set that it also needs to change. Because each row of the dsSpecials data set contains a distinct URL in the url column, the dsIngredients data set must update to include the correct URL for the selected row.
By default, the dsIngredients data set (whose data is displayed in the detail region) is created using the data it obtains from the URL specified in the constructor—in this case a reference to the data in the url column of the dsSpecials data set. The default current row in the dsSpecials data set (the first row) contains a unique path to the summersalad.xml file, and thus the detail region displays the information from that file when the page loads in a browser. When the current row of the dsSpecials data set changes, however, the URL also changes—to salmon.xml for example—and the dsIngredients data set (and by association, the detail dynamic region) updates accordingly.
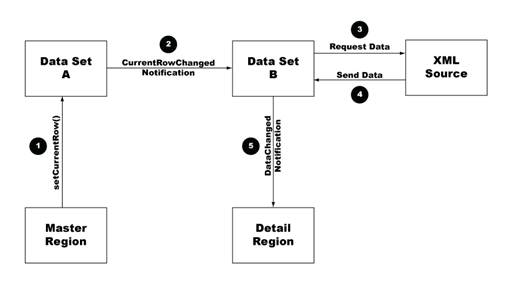
This process is functionally equivalent to the one illustrated in Spry basic master/detail region overview and structure, the technical difference being that in the advanced case, the second (or detail) data set is listening for data and row changes in the master data set, whereas in the basic example, the detail region is listening for data and row changes in the master data set.
In the example code, spry:region is used for the detail region instead of spry:detailregion. The difference between a spry:region and a spry:detailregion is that the spry:detailregion specifically listens for CurrentRowChange notifications (in addition to DataChanged notifications) from the data set, and updates itself when it receives one. Because the current row of the dsIngredients data set never changes (it's the current row of the dsSpecials data set that changes), a spry:detailregion attribute is not needed. In this case, the spry:region attribute, which defines a region that only listens for DataChanged notifications, suffices.
Progressive enhancement writes code for a document for the lowest common denominator of browser functionality and then enhances the presentation and behavior of the page, using CSS, JavaScript, Flash, Java, and SVG code, and so on. Pages created with this approach provide an enhanced experience in modern browsers, but the data is still accessible and the page still functional in the absence of these technologies.
All of the Spry examples in this document up to this point have dealt with using JavaScript to dynamically load XML data and generate regions of the document. You can also use Spry in a progressive enhancement manner using the Hijax methodology (see http://domscripting.com/blog/display/41). This progressive enhancement methodology uses JavaScript to unobtrusively attach event handlers to items on the page, such as links to catch user events (for example, clicks). Progressive enhancement also lets you replace parts of your document with code fragments that are delivered asynchronously from the server to avoid having to load an entire page.
As a trivial example of using Spry with this methodology, you could start with an HTML page filled with static data and links:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http://www.w3.org/1999/xhtml" xmlns:spry="http://ns.adobe.com/spry"> <head> <meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1" /> <title>Hijax Demo - Notes 1</title> </head> <body> <a href="notes1.html">Note 1</a> <a href="notes2.html">Note 2</a> <a href="notes3.html">Note 3</a> <div> <p>This is some <b>static content</b> for note 1.</p> </div> </body> </html>
To progressively enhance this page with Spry, so that you don't have to load an entirely new page when you click the links, you first use XML to make sure that the page fragments of each page that the links refer to are accessible. The following example is one way to externalize the static data:
<?xml version="1.0" encoding="iso-8859-1"?> <notes> <note><![CDATA[<p>This is some <b>dynamic content</b> for note 1.</p>]]></note> <note><![CDATA[<p>This is some <b>dynamic content</b> for note 2.</p>]]></note> <note><![CDATA[<p>This is some <b>dynamic content</b> for note 3.</p>]]></note> </notes>
You can then apply Spry to the HTML page in the following manner:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xmlns:spry="http://ns.adobe.com/spry">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1" />
<title>Hijax Demo - Notes 1</title>
<script language="JavaScript" type="text/javascript" src="includes/xpath.js"></script>
<script language="JavaScript" type="text/javascript" src="includes/SpryData.js"></script>
<script language="JavaScript" type="text/javascript">
<!--
var dsNotes = new Spry.Data.XMLDataSet('data/notes.xml', "/notes/note");
-->
</script>
</head>
<body>
<a href="note1.html" onclick="dsNotes.setCurrentRowNumber(0); return false;">Note 1</a>
<a href="note2.html" onclick="dsNotes.setCurrentRowNumber(1); return false;">Note 2</a>
<a href="note3.html" onclick="dsNotes.setCurrentRowNumber(2); return false;">Note 3</a>
<div spry:detailregion="dsNotes" spry:content="{note}">
<p>This is some <b>static content</b> for note 1.</p>
</div>
</body>
</html>
The Spy code added in the preceding code looks familiar, but you'll notice that the div block that includes the spry:detailregion attribute also includes a spry:content attribute. This spry:content attribute tells the Spry dynamic-region processing code to replace the static data, currently contained in the region, with the data represented by the data reference in its attribute value, if any data is in the data set that the region is bound to.
If this page is loaded in a browser with JavaScript disabled, it degrades and you get the same functionality as for the original page with static content and traditional link navigation. If JavaScript is enabled, the data set loads the XML data and replaces the static content in the region. Clicking the links updates the region with code from the data set.
In the preceding example, Hijax promotes the use of unobtrusively attaching event handlers to links. The preceding example intentionally uses onclick attributes to quickly illustrate the point of attaching a JavaScript event handler.
Before you begin creating Spry data sets, obtain the necessary files (xpath.js and SpryData.js). The xpath.js file allows you to specify complex XPath expressions when creating your data set; the SpryData.js file contains the Spry data library.
Link both files to whatever HTML page you're creating.
After you've created the data set, create a dynamic region so that you can display the data.
After you create a Spry data set, you bind a Spry dynamic region to the data set. A Spry dynamic region is an area on the page that displays the data and automatically updates the data display whenever the data set is modified.
The following sample code creates a Spry data set and dynamic region to display a list of menu specials in an HTML table.
<head>
...
<script type="text/javascript" src="includes/xpath.js"></script>
<script type="text/javascript" src="includes/SpryData.js"></script>
<script type="text/javascript">
var dsSpecials = new Spry.Data.XMLDataSet("data/cafetownsend.xml", "specials/menu_item");
</script>
...
</head>
<body>
...
<div id="Specials_DIV" spry:region="dsSpecials">
<table id="Specials_Table">
<tr>
<th>Item</th>
<th>Description</th>
<th>Price</th>
</tr>
<tr spry:repeat="dsSpecials">
<td>{item}</td>
<td>{description}</td>
<td>{price}</td>
</tr>
</table>
</div>
...
</body>
You can spry:sort attributes to your dynamic region that allow users to interact with the data.
By default, all data in the data set (including numbers) is considered text, and sorts alphabetically. To sort numerically (for example, to sort by price of menu item), you can use the setColumnType data set method to change the data type of the price column from text to numbers. The method takes the following form:
datasetName.setColumnType("columnName", "number");
Using the preceding example, you would add the setColumnType method to the head tag of your document, after you create the data set (in bold):
<script type="text/javascript">
var dsSpecials = new Spry.Data.XMLDataSet("data/cafetownsend.xml", "specials/menu_item");
dsSpecials.setColumnType("price", "number");
</script>
The expression calls the setColumnType method on the dsSpecials data set object, which you've already defined. The setColumnType method takes two parameters: the name of the data set column to retype ("price") and the desired data type ("number").
You can now add the spry:sort attribute to the price column so that all three columns in the HTML table are sortable when the user clicks any of the table headers:
<div id="Specials_DIV" spry:region="dsSpecials">
<table id="Specials_Table" class="main">
<tr>
<th spry:sort="item">Item</th>
<th spry:sort="description">Description</th>
<th spry:sort="price">Price</th>
</tr>
<tr spry:repeat="dsSpecials">
<td>{item}</td>
<td>{description}</td>
<td>{price}</td>
</tr>
</table>
</div>
When working with Spry data sets, you can create master and detail dynamic regions to display more detail about your data. One region on the page (the master), drives the display of the data in another region on the page (the detail).
You can create master and detail relationships that involve more than one data set.
By default, Spry data sets use the HTTP GET method to retrieve XML data. The data set can also retrieve data using the HTTP POST method, by specifying additional constructor options, as follows:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1" />
<title>Dynamic Region Example</title>
<script type="text/javascript" src="../../includes/xpath.js"></script>
<script type="text/javascript" src="../../includes/SpryData.js"></script>
<script type="text/javascript">
var dsPhotos = new Spry.Data.XMLDataSet("/photos.php", "/gallery/photos/photo", { method: "POST", postData: "galleryid=2000&offset=20&limit=10", headers: { "Content-Type": "application/x-www-form-urlencoded; charset=UTF-8" } });
</script>
</head>
. . .
<body>
</body>
</html>
If you use the POST method, but don't specify a content type, the default content type is set to "application/x-www-form-urlencoded; charset=UTF-8".
The following table shows the HTTP-related constructor options that you can specify.
| Option |
Description |
|---|---|
method |
The HTTP method to use when fetching the XML data. Must be the string "GET" or "POST". |
postData |
Can be a string containing url encode form arguments or any value supported by the XMLHttpRequest object. If a "Content-Type" header is not specified in conjunction with the postData option, the "application/x-www-form-urlencoded; charset=UTF-8" content type is used. |
username |
The server username to use when accessing the XML data. |
password |
The password to use in conjunction with username when accessing the XML data. |
headers |
An object or associative array that uses the HTTP request field name as its property and key to store values. |
By default, Spry caches any XML datathat a data set loaded on the client. If a data set attempts to load the XML data for a given URL that is already in the cache, Spry returns a reference to the cached data to the data set. If multiple data sets attempt to load the same URL at the same time, all load requests are combined into a single HTTP request to save bandwidth.
Use of data caching and of combining requests can greatly improve performance, especially when multiple data sets refer to the same XML data; at times you might need to load the data directly from the server (for example, if you have a URL that might return different data each time someone accesses it).
To force a data set to load XML data directly from the server, set the useCache XMLDataSet constructor option to false, as follows:var dsPhotos = new Spry.Data.XMLDataSet("/photos.php?galleryid=2000", "/gallery/photos/photo", {useCache: false })
After the XML data is loaded, it is flattened into a tabular format. Inside the data set, the data is actually stored as an array of objects (rows) with properties (columns) and values.
The following example shows data selected with the /gallery/photos/photo XPath, in bold:
<gallery id="12345"> <photographer id="4532">John Doe</photographer> <email>john@doe.com</email> <photos id="2000"> <photo path="sun.jpg" width="16" height="16"/> <photo path="tree.jpg" width="16" height="16"/> <photo path="surf.jpg" width="16" height="16"/> </photos> </gallery>
The data set then flattens the set of nodes into a tabular format, that the following table represents.
| @path |
@width |
@height |
|---|---|---|
sun.jpg |
16 |
16 |
tree.jpg |
16 |
16 |
surf.jpg |
16 |
16 |
You can get all of the rows in the data set by calling getData(). The data is loaded asynchronously, so you can only access the data after it is loaded. You might need to register an observer to be notified when the data is ready.
Use the getData() method to fetch all the rows in the data set. To get the value of a specific column, index into the row with the column name.var dsPhotos = new Spry.Data.XMLDataSet("/photos.php?galleryid=2000", "/gallery/photos/photo");
...
var rows = dsPhotos.getData(); // Get all rows.
var path = rows[0]["@path"]; // Get the data in the "@path" column of the first row.
var dsPhotos = new Spry.Data.XMLDataSet("/photos.php?galleryid=2000", "/gallery/photos/photo");
...
dsPhotos.sort("@path"); // Sort the rows of the data set using the "@path" column.
Calling the sort() method of a data set sorts the rows in ascending order, using data in the specified column.
The sort() method takes two arguments. The first argument can be the name of the column, or an array of column names to use when sorting. If the first argument is an array, the first element of the array serves as the primary sort column; each column after that is used for secondary and tertiary sorting, and so on. The second argument is the sort order to use, and must be one of the following strings: "ascending", "descending", or "toggle". If the second argument is not specified, the sort order defaults to "ascending". Specifying "toggle" as the sort order causes the data sorted in "ascending" order to be sorted in "descending" order, and the reverse. If the column was never sorted before, and the sort order used is "toggle", the data is initially sorted in "ascending" order.
var dsPhotos = new Spry.Data.XMLDataSet("/photos.php?galleryid=2000", "/gallery/photos/photo");
...
dsPhotos.sort("@path", "toggle"); // Toggle the Sort order of the rows of the data set using the "@path" column.
To have the data in the data set sorted automatically whenever data is loaded, specify the column to sort by and the sort order to use as an option to the data set constructor. Use the "sortOnLoad" option to the data set constructor to specify a column to sort by. In the following example, the data set automatically sorts in descending order by using the data in the @path column.
var dsPhotos = new Spry.Data.XMLDataSet("/photos.php?galleryid=2000", "/gallery/photos/photo", { sortOnLoad: "@path", sortOrderOnLoad: "descending" });
By default, all values in the data set are treated as text. This can be problematic when sorting numeric or date values. You can specify the data type for a given column by calling the setColumnType() method.
var dsPhotos = new Spry.Data.XMLDataSet("/photos.php?galleryid=2000", "/gallery/photos/photo");
dsPhotos.setColumnType("@width", "number");
dsPhotos.setColumnType("@height", "number");
...
dsPhotos.sort("@width"); // Sort the rows of the data set using the "@width" column.
Current supported data types are "number", "date", and "string".
Each data set maintains the notion of a current row. By default, the current row is set to the first row in the data set. To change the current row programmatically, call the setCurrentRowNumber() method and pass the row number of the row you want to make the current row. The index of the first row is always zero, so if a data set contains 10 rows, the index of the last row is 9.
Use setCurrentRowByNumber() or setCurrentRow() to change the current row:var dsPhotos = new Spry.Data.XMLDataSet("/photos.php?galleryid=2000", "/gallery/photos/photo");
...
dsPhotos.setCurrentRowNumber(2); // Make the 3rd row in the data set the current row.
Each row in the data set is also assigned a unique ID that allows you to refer to a specific row in the data set even after the order of the rows in the data set change. You can get the ID of a row by accessing its "ds_RowID" property. You can also change the current row by calling setCurrentRow() and passing the row ID of the row to make the current row.
var dsPhotos = new Spry.Data.XMLDataSet("/photos.php?galleryid=2000", "/gallery/photos/photo");
...
var id = dsPhotos.getData()[2]["ds_RowID"]; // Get the ID of the 3rd row.
...
dsPhotos.setCurrentRow(id); // Make the 3rd row the current row by using its ID.
var dsPhotos = new Spry.Data.XMLDataSet("/photos.php?galleryid=2000", "/gallery/photos/photo");
...
dsPhotos.distinct(); // Remove all duplicate rows.
In this context, the term duplicate row applies to a situation in which every column in the data set contains identical information in 2 or more rows.
To run the distinct() method automatically whenever data is loaded into a data set, use the "distinctOnLoad" option to the constructor.
var dsPhotos = new Spry.Data.XMLDataSet("/photos.php?galleryid=2000", "/gallery/photos/photo", { distinctOnLoad: true });
The distinct() method is destructive, so it discards any nondistinct rows. The only way to get the data back is to reload the XML data.
Data sets support both destructive and non-destructive filtering.
Before using either method of filtering, supply a filter function that takes a data set, row object and rowNumber. This function is invoked by the data sets filtering methods for each row in the data set. The function must return either the row object passed to the function, or a new row object, meant to replace the row passed into the function. For the function to filter out the row, it should return a null value.
The data set's destructive filter method is filterData(). This method actually replaces or discards the rows of the data set. The only way to get the original data back is to reload the XML data of the data set.
Use the destructive filterData() method to permanently discard rows in a data set:...
// Filter out all rows that don't have a path that begins
// with the letter 's'.
var myFilterFunc = function(dataSet, row, rowNumber)
{
if (row["@path"].search(/^s/) != -1)
return row; // Return the row to keep it in the data set.
return null; // Return null to remove the row from the data set.
}dsPhotos.filterData(myFilterFunc); // Filter the rows in the
data set.
The filter function remains active, even when loading XML data from another URL, until you call filterData() with a null argument. Call filterData() with a null argument to uninstall your filter function.
dsPhotos.filterData(null); // Turn off destructive filtering.
The data set's nondestructive filter method is filter(). Unlike filterData(), filter() creates a new array of rows that reference the original data. As long as the filter function does not modify the row object passed into it, you can get the original data back by calling filter() and passing a null argument. Use the nondestructive filter() method to filter the rows in a data set.
var dsPhotos = new Spry.Data.XMLDataSet("/photos.php?galleryid=2000", "/gallery/photos/photo");
...
// Filter out all rows that don't have a path that begins
// with the letter 's'.
var myFilterFunc = function(dataSet, row, rowNumber)
{
if (row["@path"].search(/^s/) != -1)
return row; // Return the row to keep it in the data set.
return null; // Return null to remove the row from the data set.
}dsPhotos.filter(myFilterFunc); // Filter the rows in the data
set.
To get the original data back, call filter() and pass a null argument
dsPhotos.filter(null); // Turn off non-destructive filtering.
Data sets can reload their data at a specified interval expressed in milliseconds. This can be handy when the data at a given URL changes periodically.
To tell a data set to load at a given interval, pass the optional loadInterval option when calling the XMLDataSet constructor:// Load the data every 10 seconds. Turn off the cache to make sure we get it directly from the server.
var dsPhotos = new Spry.Data.XMLDataSet("/photos.php?galleryid=2000", "/gallery/photos/photo", { useCache: false, loadInterval:
10000 });
You can also turn on this interval loading programatically with the startLoadInterval() method, and stop it with the stopLoadInterval() method.
dsPhotos.startLoadInterval(10000); // Start loading data every 10 seconds. ... dsPhotos.stopLoadInterval(); // Turn off interval loading.
The XML data set supports an observer mechanism that allows an object or callback function to receive event notifications.
| Notification |
Description |
|---|---|
onPreLoad |
The data set is about to send a request for data. If the data set depends on other data sets, this event notification will not send until they are all loaded successfully. |
onPostLoad |
The request for data was successful. The data is accessible. |
onLoadError |
An error occurred while requesting the data. |
onDataChanged |
The data in the data set has been modified. |
onPreSort |
The data in the data set is about to be sorted. |
onPostSort |
The data in the data set has been sorted. |
onCurrentRowChanged |
The data set's notion of the current row has changed. |
To receive notifications, an object must define a method for each notification it is interested in receiving, and then register itself as an observer on the data set. For example, an object interested in onDataChanged notifications must define an onDataChanged() method and then call addObserver().
var dsPhotos = new Spry.Data.XMLDataSet("/photos.php?galleryid=2000", "/gallery/photos/photo");
...
var myObserver = new Object;
myObserver.onDataChanged = function(dataSet, data)
{
alert("onDataChanged called!");
};
dsPhotos.addObserver(myObserver);
The first argument for each notification method is the object that is sending the notification. For data set observers, this is always the dataSet object. The second argument is either undefined, or an object that depends on the type of notification.
| Notification |
Data passed into notification |
|---|---|
onPreLoad |
undefined |
onPostLoad |
undefined |
onLoadError |
The Spry.Utils.loadURL.Request object that was used when making the request |
onDataChanged |
undefined |
onPreSort |
Object with the following properties: |
oldSortColumns: An array of columns used during the last sort. |
|
oldSortOrder: The sort order used during the last sort. |
|
newSortColumns: The array of columns about to be used for the sort. |
|
newSortOrder: The sort order about to be used for the sort. |
|
onPostSort |
Object with the following properties: |
oldSortColumns: An array of the columns used in the previous sort. |
|
oldSortOrder: The sort order used during the previous sort. |
|
newSortColumns: The array of columns used for the sort. |
|
newSortOrder: The sort order used for the sort. |
|
onCurrentRowChanged |
Object with the following properties: |
oldRowID: The ds_RowID of the last current row. |
|
newRowID: The ds_RowID of the current row. |
To stop an object from receiving notifications, the object must be removed from the list of observers with a call to removeObserver().
var dsPhotos = new Spry.Data.XMLDataSet("/photos.php?galleryid=2000", "/gallery/photos/photo");
...
dsPhotos.removeObserver(myObserver);
Functions can also be registered as observers. The main difference between object and function observers is that an object is only notified for the notification methods it defines, whereas a function observer is called for every type of event notification.
var dsPhotos = new Spry.Data.XMLDataSet("/photos.php?galleryid=2000", "/gallery/photos/photo");
...
function myObserverFunc(notificationType, dataSet, data)
{
if (notificationType == "onDataChanged")
alert("onDataChanged called!");
else if (notificationType == "onPostSort")
alert("onPostSort called!");
};
dsPhotos.addObserver(myObserverFunc);
A function observer is registered with the same call to addObserver.
When the function is called, the first argument to be passed into it is the notification type. This is a string that is the name of the notification. The second argument is the notifier, which in this case is the data set, and the third argument is the data for the notification.
To stop a function observer from receiving notifications, it must be removed from the list of observers with a call to removeObserver().
var dsPhotos = new Spry.Data.XMLDataSet("/photos.php?galleryid=2000", "/gallery/photos/photo");
...
dsPhotos.removeObserver(myObserverFunc);
Dynamic regions currently support two looping constructs. One allows you to repeat an element and all of its content for each row in a given data set (spry:repeat), and another allows you to repeat all of the children of a given element for each row in a given data set (spry:repeatchildren).
To designate an element as something that repeats, add a spry:repeat attribute to the element with a value that is the name of the data set to repeat. The following example shows an li block that repeats for every row in the dsPhotos data set
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xmlns:spry="http://ns.adobe.com/spry">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1" />
<title>Dynamic Region Example</title>
<script type="text/javascript" src="../../includes/xpath.js"></script>
<script type="text/javascript" src="../../includes/SpryData.js"></script>
<script type="text/javascript">
var dsPhotos = new Spry.Data.XMLDataSet("/photos.php?galleryid=2000", "/gallery/photos/photo");
</script>
</head>
<body>
<div spry:region="dsPhotos">
<ul>
<li spry:repeat="dsPhotos">{@path}</li>
</ul>
</div>
</body>
</html>
To repeat just the children of an element, use the spry:repeatchildren attribute instead. In the following example, the children of the ul tag repeats for every row in the dsPhotos data set:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xmlns:spry="http://ns.adobe.com/spry">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1" />
<title>Dynamic Region Example</title>
<script type="text/javascript" src="../../includes/xpath.js"></script>
<script type="text/javascript" src="../../includes/SpryData.js"></script>
<script type="text/javascript">
var dsPhotos = new Spry.Data.XMLDataSet("/photos.php?galleryid=2000", "/gallery/photos/photo");
</script>
</head>
<body>
<div spry:region="dsPhotos">
<ul spry:repeatchildren="dsPhotos">
<li>{@path}</li>
</ul>
</div>
</body>
</html>
The preceding "spry:repeat" and "spry:repeatchildren" examples are functionally equivalent, but "spry:repeatchildren" becomes more useful when used in conjunction with conditional constructs. Both examples result in the following output:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xmlns:spry="http://ns.adobe.com/spry">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1" />
<title>Dynamic Region Example</title>
<script type="text/javascript" src="../../includes/xpath.js"></script>
<script type="text/javascript" src="../../includes/SpryData.js"></script>
<script type="text/javascript">
var dsPhotos = new Spry.Data.XMLDataSet("/photos.php?galleryid=2000", "/gallery/photos/photo");
</script>
</head>
<body>
<div>
<ul>
<li>sun.jpg</li>
<li>tree.jpg</li>
<li>surf.jpg</li>
</ul>
</div>
</body>
</html>
If you do not want to output the content in a repeat region for every row in the data set, limit what gets written out during the loop processing by adding a spry:test attribute to the element that has the spry:repeat or spry:repeatchildren attribute on it.
The following example shows an li block that is only output if the first letter of the value of {@path} starts with the letter s:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xmlns:spry="http://ns.adobe.com/spry">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1" />
<title>Dynamic Region Example</title>
<script type="text/javascript" src="../../includes/xpath.js"></script>
<script type="text/javascript" src="../../includes/SpryData.js"></script>
<script type="text/javascript">
var dsPhotos = new Spry.Data.XMLDataSet("/photos.php?galleryid=2000", "/gallery/photos/photo");
</script>
</head>
<body>
<div spry:region="dsPhotos">
<ul>
<li spry:repeat="dsPhotos" spry:test="'{@path}'.search(/^s/)
!= -1;">{@path}</li>
</ul>
</div>
</body>
</html>
The value of this spry:test attribute can be any JavaScript expression that evaluates to zero or false or some nonzero value. If the expression returns a nonzero value, the content is output. Because you are using XHTML, any special characters like &, <, or > that might be used in a JavaScript expression need to be converted to HTML entities. You can also use data references inside this JavaScript expression and the dynamic region processing engine provides the actual values from a data set just before evaluating the spry:test expression.
The following code shows the final output of the preceding example:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xmlns:spry="http://ns.adobe.com/spry">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1" />
<title>Dynamic Region Example</title>
<script type="text/javascript" src="../../includes/xpath.js"></script>
<script type="text/javascript" src="../../includes/SpryData.js"></script>
<script type="text/javascript">
var dsPhotos = new Spry.Data.XMLDataSet("/photos.php?galleryid=2000", "/gallery/photos/photo");
</script>
</head>
<body>
<div>
<ul>
<li>sun.jpg</li>
<li>surf.jpg</li>
</ul>
</div>
</body>
</html>
Dynamic regions currently support two conditional constructs. The first is "spry:if". In the following example, the li tag is only written out if the value of {@path} begins with the letter s:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xmlns:spry="http://ns.adobe.com/spry">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1" />
<title>Dynamic Region Example</title>
<script type="text/javascript" src="../../includes/xpath.js"></script>
<script type="text/javascript" src="../../includes/SpryData.js"></script>
<script type="text/javascript">
var dsPhotos = new Spry.Data.XMLDataSet("/photos.php?galleryid=2000", "/gallery/photos/photo");
</script>
</head>
<body>
<div spry:region="dsPhotos">
<ul class="spry:repeat">
<li spry:if="'{@path}'.search(/^s/) != -1;">{@path}</li>
</ul>
</div>
</body>
</html>
To make an element conditional, add an spry:if attribute to the element with a value that is a JavaScript expression that returns zero or nonzero values. A nonzero value that the JavaScript expression returns results in the element being written to the final output.
If you need an if-else construct, use the "spry:choose" construct. The following example uses the spry:choose construct to color every other div:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xmlns:spry="http://ns.adobe.com/spry">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1" />
<title>Dynamic Region Example</title>
<script type="text/javascript" src="../../includes/xpath.js"></script>
<script type="text/javascript" src="../../includes/SpryData.js"></script>
<script type="text/javascript">
var dsPhotos = new Spry.Data.XMLDataSet("/photos.php?galleryid=2000", "/gallery/photos/photo");
</script>
</head>
<body>
<div spry:region="dsPhotos">
<div spry:choose="spry:choose">
<div spry:when="'{@path}' == 'surf.gif'">{@path}</div>
<div spry:when="'{@path}' == 'undefined'">Path was not defined.</div>
<div spry:default="spry:default">Unexpected value for path!</div>
</div>
</div>
</body>
</html>
The spry:choose construct provides functionality equivalent to a case statement, or an if-else if-else construct. To create a spry:choose structure add a spry:choose attribute to an element. Next, add one or more child elements with spry:when attributes on them. The value of a spry:when attribute should be a JavaScript expression that returns a zero or nonzero value. To have a default case, in case all of the JavaScript expressions for each spry:when attribute return zero or false, add an element with a spry:default attribute. The spry:default attribute doesn't require a value, but XHTML states that all attributes must have a value, therefore, set the value of the attribute equal to its name.
The region processing engine evaluates the spry:when attribute of each node in the order they are listed under their parent element. The spry:default element is always evaluated last, and only if no spry:when expression returns a nonzero value.
Spry supports the notion of region states. That is, at any given time, a region is either loading data, ready to display the data, or in an error state because one or more of the data sets it is bound to failed to load its data. You can place a spry:state attribute, with a value of "loading", "error", or "ready" on elements inside a region container to associate it with a specific region state. Doing so can be quite useful for displaying a loading message as the data for a region loads, or notifying the user that the region failed to get its data. As the region changes states, it automatically regenerates its code and displays any elements with a spry:state attribute that matches the current state.
The following example uses the spry:state attribute to display loading and error messages:
<div spry:region="dsEmployees">
<div spry:state="loading">Loading employee data ...</div>
<div spry:state="error">Failed to load employee data!</div>
<ul spry:state="ready">
<li spry:repeat="dsEmployees">{firstname} {lastname}</li>
</ul>
</div>
Any content that does not have a spry:state attribute on it, or is not a child or descendent of an element that has a spry:state attribute on it, is always included in the output when the code is regenerated. Also, children or descendents of an element with a spry:state attribute cannot have spry:state attributes. That is, nesting elements with spry:state attributes is not supported.
Spry supports an observer mechanism that allows a developer to register an object or function to receive a notification whenever the state of a region changes. This mechanism is almost identical to what is used for data sets with the following exceptions:
Adding and removing region observers is done through the Spry.Data.Region.addObserver() and Spry.Data.Region.removeObserver global namespaced functions. This practice is different from data sets because data set observers call addObserver() and removeObserver() methods that are on the data set object. The use of global namespaced functions allows a developer to register an observer before the document's onload event starts, and before Spry creates the JavaScript object that represents the region. Regions use addObserver and removeObserver functions because the developer might want to register observers before the JavaScript region object actually exists.
Both addObserver() and removeObserver() require an ID to identify which region the developer wants to observe. For this reason, regions that developers want to observe must have an id attribute defined on their region container node.
To receive notifications, an object must define a method for each notification it is interested in receiving, and then register itself as an observer on the region.
The following example shows an object being registered as an observer on a dynamic region:
<script>
...
// Create an observer object and define the methods to receive the notifications
// it wants.
myObserver = new Object;
myObserver.onPostUpdate = function(notifier, data)
{
alert("onPostUpdate called for " + data.regionID);
};
...
// Call addObserver() to register the object as an observer.
Spry.Data.Region.addObserver("employeeListRegion", myObserver);
...
// You can unregister your object so it stops recieving notifications
// with a call to removeObserver().
Spry.Data.Region.removeObserver("employeeListRegion", myObserver);
...
</script>
...
<ul id="employeeListRegion" spry:region="dsEmployees">
...
</ul>
The first argument for each notification method is the object that is sending the notification. For region observers, this is not the region object. The second argument is an object that contains a regionID property that identifies the region that triggered the notification.
To stop an object from receiving notifications, the object must be removed from the list of observers with a call to removeObserver().
Functions can also be registered as observers. The main difference between object and function observers is that an object is only notified for the notification methods it defines, whereas a function observer is called for every type of event notification.
The following example shows a function being registered as an observer on a dynamic region:
<script>
...
function myRegionCallback(notificationState, notifier, data)
{
if (notificationType == "onPreUpdate")
alert(regionID + " is starting an update!");
else if (notificationType == "onPostUpdate")
alert(regionID + " is done updating!");
}
...
// Call addObserver() to register your function as an observer.
Spry.Data.Region.addObserver("employeeListRegion", MyRegionCallback);
...
// You can unregister your callback function so it stops recieving notifications
// with a call to removeObserver().
Spry.Data.Region.removeObserver("employeeListRegion", MyRegionCallback);
...
</script>
...
<ul id="employeeListRegion" spry:region="dsEmployees">
...
</ul>
A function observer is registered with the same call to addObserver().
When the function is called, the first argument passed into it is the notification type. This is a string that is the name of the notification. The second argument is the notifier, which in this case is not the region object. The third argument is a data object that has a regionID property that tells us what region triggered the notification.
To stop a function observer from receiving notifications, it must be removed from the list of observers with a call to removeObserver().
The following table describes the current set of supported notifications.
| Region notification type |
Description |
|---|---|
onLoadingData |
One or more of the region's bound data sets is loading its data. |
onPreUpdate |
All of the region's bound data sets have loaded successfully. The region is about to regenerate its code. |
onPostUpdate |
The region has regenerated its code and inserted it into the document. |
onError |
An error occurred while loading data. |
Each data set has a set of built-in data references that can be useful during the dynamic region regeneration process. Like data set column names, these built-in data references must be prefixed with the name of the data set if the dynamic region is bound to more than one data set.
For example, to display the row number of the current row of the data set when the region regenerates, add the ds_RowNumber data reference to the dynamic region, as follows:
<tr spry:repeat="dsSpecials">
<td>{item}</td>
<td>{description}</td>
<td>{price}</td>
<td>{ds_RowNumber}</td>
</tr>
These options are also useful to pass a value in a JavaScript method, as follows:
<tr spry:repeat="dsSpecials" onclick="dsSpecials.setCurrentRow('{ds_RowID}')">
<td>{item}</td>
<td>{description}</td>
<td>{price}</td>
</tr>
The following table provides a full list of built-in Spry data references.
| Data reference |
Description |
|---|---|
ds_RowID |
The ID of a row in the data set. This ID can be used to refer to a specific record in the data set. It does not change, even when the data is sorted. |
ds_RowNumber |
The row number of the current row of the data set. Within a loop construct, this number reflects the position of the row currently being evaluated. |
ds_RowNumberPlus1 |
The same as ds_RowNumber, except that the first row starts at index 1 instead of index 0. |
ds_RowCount |
The number of rows in the data set. If a nondestructive filter is set on the data set, this is the total number of rows after the filter is applied. |
ds_UnfilteredRowCount |
The number of rows in the data set before any nondestructive filter is applied. |
ds_CurrentRowID |
The ID of the current row of the data set. This value does not change, even when used within a looping construct. |
ds_CurrentRowNumber |
The row number of the current row of the data set. This value does not change, even when used within a looping construct. |
ds_SortColumn |
The name of the column last used for sorting. If the data in the data set was never sorted, this outputs nothing (an empty string). |
ds_SortOrder |
The current sort order of the data in the data set. This data reference outputs the words ascending, descending, or nothing (an empty string). |
ds_EvenOddRow |
Looks at the current value of ds_RowNumber and returns the string "even" or "odd". Useful for rendering alternate row colors. |
<style>.SpryHiddenRegion
{visibility:hidden;}
</style>
...
<div spry:region="dsEmployees" class="SpryHiddenRegion">
...
</div>
Using this technique, the CSS rule hides the Spry regions marked with this class when the page loads. When the Spry data is finished processing, Spry strips off the SpryHiddenRegion class and the finished Spry content appears.
An alternative way to hide just the data references, as opposed to the whole tag, is to use the spry:content attribute as a substitute for a data reference. Because the data reference is the value of the spry:content attribute, it is not visible when the page loads.
The following example hides a data reference with a spry:content attribute on an element:
<!--Example of a normal region.-->
<div spry:region="dsEmployees">
Hello my name is {firstname}.
</div>
<!--Example of a region using spry:content.-->
Hello my name is <span spry:content="{firstname}"></span>.
</div>
The spry:content attribute replaces the entire contents of the div tag with the value of the attribute. In this case, the the value of {firstname} is inserted into the empty span tag. The result is the same, only in this case there is no visible data reference.
You can place behavior attributes on elements within a dynamic region to automatically enable common behaviors that would ordinarily require some manual programming.
The spry:hover attribute places a class name on an element whenever the mouse cursor enters the element, and removes that class name as the cursor exits the element.
The value for the spry:hover attribute is the name of the class to put on the element whenever the mouse enters or exits the element.
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xmlns:spry="http://ns.adobe.com/spry">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1" />
<title>Behavior Attributes Example</title>
<style>
.myHoverClass { background-color: yellow; }
</style>
<script type="text/javascript" src="../../includes/xpath.js"></script>
<script type="text/javascript" src="../../includes/SpryData.js"></script><script type="text/javascript">
var dsEmployees = new Spry.Data.XMLDataSet("../../data/employees-01.xml",
"/employees/employee");
</script>
</head>
<body>
<div spry:region="dsEmployees">
<ul>
<li spry:repeat="dsEmployees" spry:hover="myHoverClass">{username}</li>
</ul>
</div>
</body>
</html>
In the preceding example, whenever the mouse enters an li element, the "myHoverClass" class name is added to the element's class attribute. It is automatically removed when the mouse exits the element.
The spry:select attribute places a class name on an element when the mouse clicks the element.
The value for the spry:select attribute is the name of the class to put on the element whenever the mouse clicks the element.
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xmlns:spry="http://ns.adobe.com/spry">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1" />
<title>Behavior Attributes Example</title>
<style>
.myHoverClass {
background-color: yellow;
}
.mySelectClass { color: white; background-color: black;}
</style>
<script type="text/javascript" src="../../includes/xpath.js"></script>
<script type="text/javascript" src="../../includes/SpryData.js"></script><script type="text/javascript">var dsEmployees = new Spry.Data.XMLDataSet("../../data/employees-01.xml",
"/employees/employee");
</script>
</head>
<body>
<div spry:region="dsEmployees">
<ul>
<li spry:repeat="dsEmployees" spry:hover="myHoverClass" spry:select="mySelectClass">{username}</li>
</ul>
</div>
</body>
</html>
In the preceding example, whenever the mouse clicks an li element, the mySelectClass class name is added to the elements class attribute.
If an element on the page with a spry:select attribute was previously selected, the class name used as the value for its spry:select attribute is automatically removed, in effect unselecting that element.
You can use a spry:selectgroup attribute in conjunction with a spry:select attribute to allow you to have more than one set of selections on a page. For a working example of this, see the RSS Reader example in the demos folder of the Spry folder from Adobe Labs.
<html xmlns="http://www.w3.org/1999/xhtml" xmlns:spry="http://ns.adobe.com/spry">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1" />
<title>Behavior Attributes Example</title>
<style>
.myHoverClass {
background-color: yellow;
}
.mySelectClass { color: white; background-color: black;}
.myOtherSelectClass { color: white; background-color: black;}
</style>
<script type="text/javascript" src="../../includes/xpath.js"></script><script type="text/javascript" src="../../includes/SpryData.js"></script><script type="text/javascript">
var dsEmployees = new Spry.Data.XMLDataSet("../../data/employees-01.xml",
"/employees/employee");
</script></head><body><div spry:region="dsEmployees">
<ul>
<li spry:repeat="dsEmployees" spry:hover="myHoverClass" spry:select="mySelectClass"
spry:selectgroup="username">{username}</li> </ul>
<ul>
<li spry:repeat="dsEmployees" spry:hover="myHoverClass" spry:select="myOtherSelectClass"
spry:selectgroup="firstname">{firstname}</li>
</ul>
</div>
</body></html>
The value of a spry:selectgroup attribute is an arbitrary name. Any element that uses the same name for its spry:selectgroup attribute is automatically unselected when another element with the same select group name is clicked. Other elements with differing spry:selectgroup values are unaffected.
Copyright © 2007. Adobe Systems Incorporated.
All rights reserved